
Automated curation technologies for the digitised cultural heritage
The aim of the QURATOR project was the development of a sustainable technology platform which supports knowledge workers in different industries and application contexts in curating digital content. Artificial intelligence (AI) methods were integrated into curation technologies and industry solutions that cover the entire life cycle of content curation. As the responsible unit within the Prussian Cultural Heritage Foundation (Stiftung Preußischer Kulturbesitz, SPK) in the QURATOR project, Berlin State Library (Staatsbibliothek zu Berlin, SBB) was responsible for the sub-project "Automated curation technologies for digitised cultural heritage". Several results of the sub-project are demonstrated here, additional information is available below.

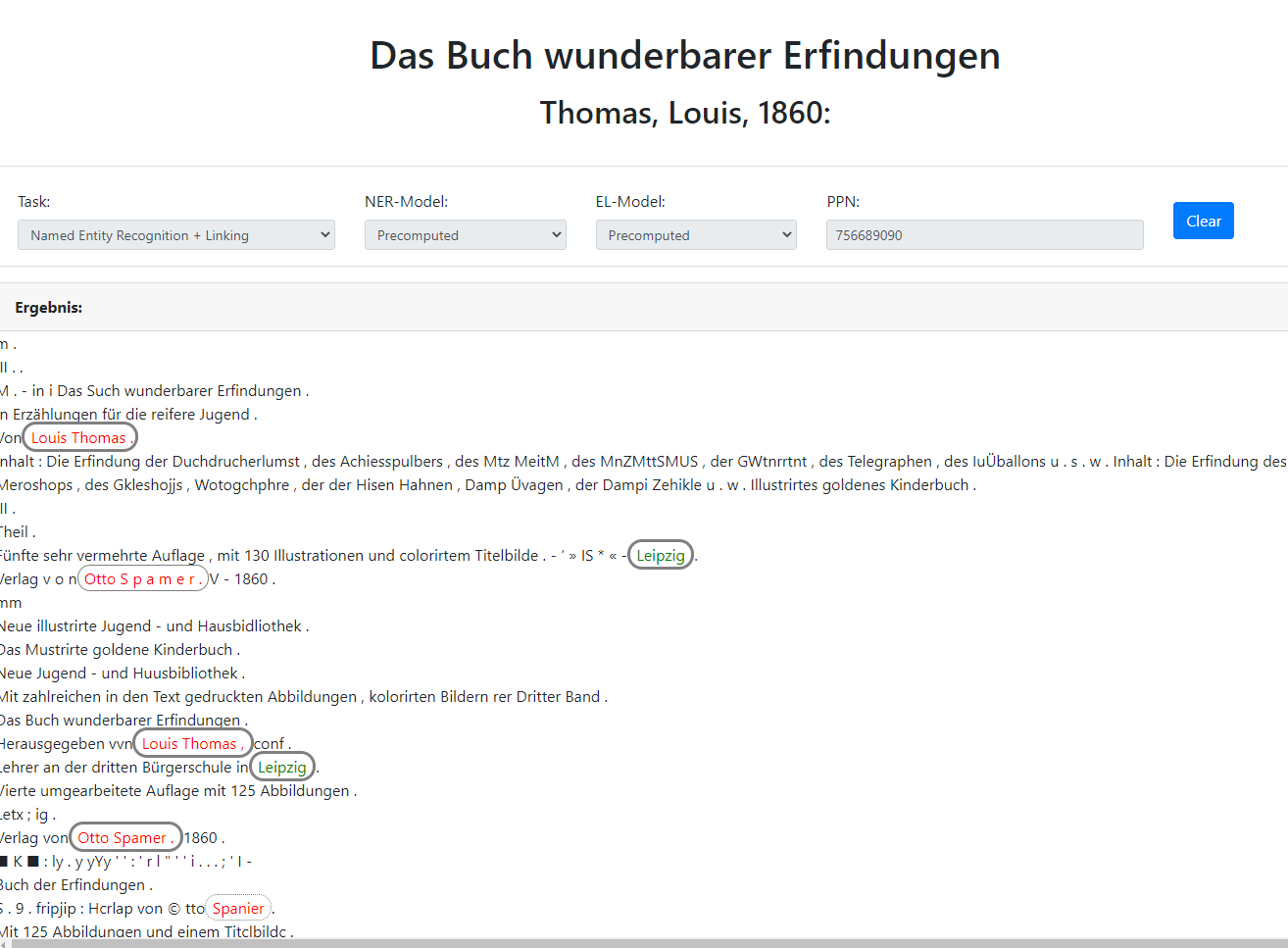
General project information and background
- Main project website
- Contact us (SBB QURATOR team)
- Interview on the role of SBB in QURATOR (German)
- Project presentation (English)
- Project presentation (German)
- Introductory blog post (German)
- Progress update blog post (German)
Software
All software tools are released as open source on GitHub.
- mods4pandas: extract metadata from METS/MODS files into a pandas DataFrame for data analysis
- sbb_binarization: binarize document images (i.e. convert to black/white)
- sbb_page_extractor: extract page border from a document image
- sbb_pixelwise_segmentation: train a classifier for pixelwise segmentation of document images
- sbb_column_classifier: determine the number of columns from document images
- eynollah: perform layout analysis and textline detection from document images
- sbb_images: tools to annotate images, to train an image classifier, for image similarity search and to extract image meta data for a large image set
- ocrd_calamari: recognize text from document images using the Calamari OCR engine with OCR-D interface
- sbb_ocr_postcorrection: automatically correct errors in OCR output
- ocrd_galley: a Dockerized test environment for QURATOR processors with OCR-D interfaces
- dinglehopper: OCR evaluation with visual word/character differences report
- sbb_ner: Named Entity Recognition for historical and contemporary German
- sbb_ned: Named Entity Disambiguation and Linking
- sbb_knowledge-base: tools for Wikidata/Wikipedia knowledge-base extraction
- neat: simple Browser-based tool for Named Entity Annotation and OCR correction
- sbb_topic-modelling: tools for topic modelling of SBB digitized collections
- page2tsv: convert PAGE-XML to tab-separated-values
- page2img: plot visualization of layout analysis from PAGE-XML data
Models
In order to use the software tools, you can obtain our trained models from here.
- models for sbb_binarization
- models for sbb_pixelwise_segmentation
- models for eynollah
- models for sbb_images
- models for Calamari OCR engine
- models for sbb_ner
- models for sbb_ned
Datasets
All datasets are released with open licenses on Zenodo.
- extracted fulltexts (OCR) of the digital collections of SBB
- extracted images (part 1) of the digital collections of SBB
- extracted images (part 2) of the digital collections of SBB
- extracted images (part 3) of the digital collections of SBB
- extracted images (part 4) of the digital collections of SBB
- extracted metadata of the main library catalogue of SBB
Publications
All scientific publications are available open access.
- Clemens Neudecker: Cultural Heritage as Data: Digital Curation and Artificial Intelligence in Libraries. In: Adrian Paschke and Georg Rehm and Clemens Neudecker and Lydia Pintscher (editors): Proceedings of the 3rd Conference on Digital Curation Technologies (Qurator) 2022, Berlin, Germany, September 19-23, 2022. CEUR Workshop Proceedings vol. 3234.
- Kai Labusch, Clemens Neudecker: Entity Linking in Multilingual Newspapers and Classical Commentaries with BERT. In: Guglielmo Faggioli and Nicola Ferro and Allan Hanbury and Martin Potthast (editors): Proceedings of the Working Notes of CLEF 2022 - Conference and Labs of the Evaluation Forum, Bologna, Italy, September 5-8, 2022. CEUR Workshop Proceedings vol. 3180.
- Clemens Neudecker: Zur Kuratierung digitalisierter Dokumente mit Künstlicher Intelligenz: Das Qurator-Projekt. In: Erda Lapp, Silke Sewing, Renate Zimmermann, Willi Bredemeier (editors): Bibliotheken. Wegweiser in die Zukunft, Simon Verlag für Bibliothekswissen, 2021, pp. 204-231.
- Clemens Neudecker, Konstantin Baierer, Mike Gerber, Christian Clausner, Apostolos Antonacopoulos, Stefan Pletschacher: A survey of OCR evaluation tools and metrics. In: Apostolos Antonacopoulos, Christian Clausner, Maud Ehrmann, Clemens Neudecker, Stefan Pletschacher (editors): Proceedings of the 6th International Workshop on Historical Document Imaging and Processing (HIP) 2021, Lausanne, Switzerland, September 6, 2021.
- Sina Menzel, Hannes Schnaitter, Josefine Zinck, Vivien Petras, Clemens Neudecker, Kai Labusch, Elena Leitner, Georg Rehm: Named Entity Linking mit Wikidata und GND – Das Potenzial handkuratierter und strukturierter Datenquellen für die semantische Anreicherung von Volltexten. In: Michael Franke-Maier, Anna Kasprzik, Andreas Ledl, Hans Schürmann (editors): Qualität in der Inhaltserschließung. Berlin/Boston, De Gruyter Saur, 2021, pp. 229–257.
- Clemens Neudecker, Karolina Zaczynska, Konstantin Baierer, Georg Rehm, Mike Gerber, Julian Moreno Schneider: Methoden und Metriken zur Messung von OCR-Qualität für die Kuratierung von Daten und Metadaten. In: Michael Franke-Maier, Anna Kasprzik, Andreas Ledl, Hans Schürmann (editors): Qualität in der Inhaltserschließung. Berlin/Boston, De Gruyter Saur, 2021, pp. 137-166.
- Robin Schäfer, Clemens Neudecker: A Two-Step Approach for Automatic OCR Post-Correction. In: Stefania DeGaetano, Anna Kazantseva, Nils Reiter, Stan Szpakowicz (editors): Proceedings of the 4th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature (LaTeCH-CLfL) 2020, Barcelona, Spain, June 15, 2020.
- Kai Labusch, Clemens Neudecker: Named Entity Disambiguation and Linking on Historic Newspaper OCR with BERT. In: Linda Cappellato, Carsten Eickhoff, Nicola Ferro, Aurélie Névéol (editors): Working Notes of CLEF 2020 - Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, September 22-25, 2020. CEUR Workshop Proceedings vol. 2696.
- Georg Rehm, Peter Bourgonje, Stefanie Hegele, Florian Kintzel, Julián Moreno Schneider, Malte Ostendorff, Karolina Zaczynska, Armin Berger, Stefan Grill, Sören Räuchle, Jens Rauenbusch, Lisa Rutenburg, André Schmidt, Mikka Wild, Henry Hoffmann, Julian Fink, Sarah Schulz, Jurica Seva, Joachim Quantz, Joachim Böttger, Josefine Matthey, Rolf Fricke, Jan Thomsen, Adrian Paschke, Jamal Al Qundus, Thomas Hoppe, Naouel Karam, Frauke Weichhardt, Christian Fillies, Clemens Neudecker, Mike Gerber, Kai Labusch, Vahid Rezanezhad, Robin Schaefer, David Zellhöfer, Daniel Siewert, Patrick Bunk, Lydia Pintscher, Elena Aleynikova, Franziska Heine: QURATOR: Innovative Technologies for Content and Data Curation. In: Adrian Paschke, Clemens Neudecker, Georg Rehm, Jamal al-Qundus, Lydia Pintscher (editors): Proceedings of the 1st Conference on Digital Curation Technologies (QURATOR) 2020, Berlin, Germany, January 20-21, 2020. CEUR Workshop Proceedings vol. 2535.
- Kai Labusch, Clemens Neudecker, David Zellhöfer: BERT for Named Entity Recognition in Contemporary and Historic German. In: Proceedings of the 15th Conference on Natural Language Processing (KONVENS) 2019, Erlangen, Germany, October 9-11, 2019.
- David Zellhöfer: Multimodal Datasets of the Berlin State Library. In: Thierry Declerck, John P. McCrae (editors): Proceedings of the Poster Session of the 2nd Conference on Language, Data and Knowledge (LDK) 2019, Leipzig, Germany, May 21, 2019. CEUR Workshop Proceedings vol. 2402.